|
Projekt zur robusten Spracherkennung mit Hilfe einer Aadption der Hidden Markov ModelleLaufzeit: April 2004 bis Juni 2008
Förderung: durch die DFG (Deutschen Forschungsgemeinschaft)
Die nachstehend beschriebenen Arbeiten und Ergebnisse wurden auch in einem Abschlussbericht dokumentiert:
1) Simulation der Spracheingabe in einer gestörten Umgebung
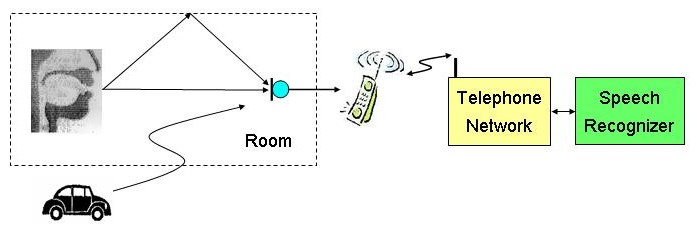
Die meisten bisherigen Untersuchungen im Bereich der robusten Erkennung konzentrieren sich auf den Einfluß von Hintergundstörungen bei der Spracheingabe und/oder das Vorhandensein von Frequenzgangveränderungen durch ein Mikrofon oder einen Übertragungskanal. • die hallige Umgebung eines Raumes im Fall von Freisprechen, • das Vorhandensein von Hintergrundstörungen, • die im Telefoniebereich typischen Frequenzgangveränderung und • die Übertragung über einen gestörten Mobilfunkkanal simuliert werden können.
2) Erzeugung gestörter Sprachdaten und ErkennungsexperimenteIn der nächsten Phase des Projekts wurden die Auswirkungen der einzelnen Störeinflüsse als auch einer Kombination von Einflüssen auf die Spracherkennung untersucht. Dabei erfolgt eine Beschränkung auf Situationen der Spracheingabe, wie sie in den für den sinnvollen, praktischen Einsatz von Spracherkennungsystem typischen Fällen auftreten. Es werden beispielsweise das Freisprechen in einem Kraftfahrzeug oder in einer Büroumgebung betrachtet. Dabei kann die Spracheingabe zur Steuerung lokaler Geräte oder zum Abruf von Informationen über Telefon erfolgen. Als ein Ergebnis dieses Projektabschnitts wurde ein Teil der zur Durchführung der Untersuchungen erzeugten gestörten Sprachdaten in Form einer Sprachdatenbasis mit der Bezeichnung "Aurora-5" zusammengestellt. Aurora-5 beinhaltet gestörte Versionen der bekannten TIDigits Datenbasis, die Äußerungen englischer Ziffernfolgen von amerikanischen Sprechern beinhaltet ==> Informationen zu Aurora-5 Die Datenbasis steht den in diesem Bereich Forschenden zur Durchführung vergleichender Untersuchungen zur Verfügung. Die Bereitstellung erfolgt durch die zur Verteilung von Sprachdaten im europäischen Umfeld tätige Organisation ELRA (European Language Resources Association).
3) HMM Adaption zur Kompensation des Nachhalls
Als ein weiteres Ergebnis dieses Projekts wurde ein neues Verfahren zur Adaption der Hidden-Markov Modelle (HMMs), die als Referenzmuster zur Spracherkennung eingesetzt werden, entwickelt. Damit können die in den HMMs enthaltenen akustischen Merkmale auf eine Spracheingabe im Freisprechmodus in räumlichen Umgebungen angepasst werden. Der Nachhall tritt dabei als ein die zeitliche Struktur der Sprache verändernder Effekt auf. Basierend auf einem Modell, mit dem die zeitliche Veränderung des Energieverlaufs insgesamt und in spektralen Teilbändern beschrieben werden kann, werden die Energie und die spektralen Merkmalsparameter in den HMMs adaptiert. Damit lässt sich eine deutliche Verbesserung der Erkennungsraten bei einer Spracheingabe im Freisprechmodus erzielen. Das Verfahren und die damit erzielten Erkennungsergebnisse werden vorgestellt in • H.G. Hirsch: "Automatic Speech Recognition in Adverse Acoustic Conditions", Kapitel des Buchs "Advances in Digital Speech Transmission", Verlag John Wiley & sons, 2008 • H.G. Hirsch, Finster, H.: "A New Approach for the Adaptation of HMMs to Reverberation and Background Noise", Speech Communication, Vol.50, pp. 244-263, 2008.
4) Kombination einer Extraktion robuster akustischer Merkmale Spracherkennung mit der HMM AdaptionAbschließend konnte gezeigt werden, dass das neue Verfahren zur HMM Adaption auch mit einem bestehenden Verfahren zur Extraktion robuster akustischer Merkmale kombiniert werden kann. Bei dem Merkmalsextraktionsverfahren, das von ETSI standardisiert wurde, handelt es sich um eine Cepstralanalyse mit einem vorgeschalteten Störunterdrückungsverfahren. Durch die Kombination mit der HMM Adaption kann die Erkennung von Sprachsignalen, die in einer gestörten räumlichen Umgebung im Freisprechmodus aufgenommen werden, deutlich verbessert werden. |